
この記事には広告を含む場合があります。
記事内で紹介する商品を購入することで、当サイトに売り上げの一部が還元されることがあります。
「HighLow」のバイナリーオプションは、判定時刻における為替レートが現在のレートよりも高くなるか低くなるかを予測する取引です。トレーダーにとって、予測の精度を高めることは利益を最大化する鍵となります。
この記事では、Pythonを使って1時間後の価格が現在の価格より上昇するか下降するかを予測する機械学習プログラムを作成する方法について解説します。
初心者でも簡単に実践できるように進めていきますので、ぜひチャレンジしてみてください。
\口座開設と取引で5,000円のボーナス!/
バイナリーオプションとは
バイナリーオプションでは、判定時刻における為替レートが現在のレートよりも高くなるか低くなるかを予測します。例えば、1ドル=150円のときに為替レートが上昇すると予測した場合、満期時に1ドル=150円を超えていれば利益を得られます。予測が外れた場合は、購入したオプション代金分の損失となります。
必要なライブラリのインストール
予測プログラムを作成するには、以下のライブラリをインストールしてください。
- yfinance:Yahoo Financeから価格データを取得します。
- scikit-learn:機械学習モデルの作成に使用します。
- XGboost:機械学習のアルゴリズムのライブラリ。
- matplotlib:グラフの作成に使用します。
各ライブラリをpipでインストールします。
pip install yfinance
pip install scikit-learn
pip install xgboost
pip install matplotlib予測プログラムのサンプルコード
以下のコードがラダーオプションの予測プログラムです。
import time
from datetime import datetime
from datetime import timedelta
import pandas as pd
import yfinance as yf
import talib
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
pair = "USDJPY=X" # ドル/円
timeframe = "5m" # 5分足
number_of_days = 60 # 四本値を取得する日数
# FXの価格データを取得
start = datetime.today().date() - timedelta(days=1)
end = datetime.today().date()
df = yf.download(pair, interval=timeframe, start=start)
for i in range(number_of_days):
start = start - timedelta(days=1)
end = end - timedelta(days=1)
df_reserve = yf.download(pair, interval=timeframe, start=start, end=end)
df = pd.concat([df_reserve, df])
time.sleep(0.1)
# ターゲット変数の作成
# 現在の価格と60分後の価格を比較して、上昇なら1、下降なら0とする
df['future_price'] = df['Close'].shift(-12) # 60分後の価格
columns = ['Close', 'future_price']
df_reserve = df[columns].diff(axis=1)
df_reserve['Close_diff'] = df_reserve['future_price']
df = pd.concat([df, df_reserve['Close_diff']], axis=1)
df['target'] = (df['future_price'] > df['Close']).astype(int)
df = df.dropna(subset=['future_price'])
# 特徴量エンジニアリング
# 移動平均やボラティリティ、価格変化率などを特徴量にする
df['date'] = df.index.values
df['hour'] = df['date'].dt.hour
df['minute'] = df['date'].dt.minute
df['MA'] = talib.MA(df['Close'], timeperiod=20).diff()
df['BBANDS_U'], _, df['BBANDS_L'] \
= talib.BBANDS(df['Close'], timeperiod=20, nbdevup=2, nbdevdn=2, matype=0)
df['BBANDS_U'] = df['BBANDS_U'].diff()
df['BBANDS_L'] = df['BBANDS_L'].diff()
df['MACD'], df['MACDsignal'], df['MACDhist'] \
= talib.MACD(df['Close'], fastperiod=12, slowperiod=26, signalperiod=9)
df['RSI'] = talib.RSI(df['Close'], timeperiod=14)
# 訓練データとテストデータに分割
features = ['hour', 'minute', 'MA', 'BBANDS_U', 'BBANDS_L', 'MACD', 'MACDsignal', 'MACDhist', 'RSI']
X = df[features]
y = df['target']
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 学習モデルを作成
model = xgb.XGBClassifier(n_estimators=100, max_depth=6, learning_rate=0.1, random_state=0)
# 学習モデルにテストデータを与えて学習させる
model.fit(X_train, y_train)
# テストデータを与えて各データの種類を推測
test = model.predict(X_test)
# テストデータのラベルを与えて答え合わせ
score = accuracy_score(y_test, test)
print(f"正解率:{score * 100:.1f}%")
# 直近のデータで30分後の価格予測
latest_data = X.iloc[-1].values.reshape(1, -1)
prediction = model.predict(latest_data)
print(f'60分後の価格予測: {"上昇" if prediction[0] == 1 else "下降"}')
# 各特徴量の重要度の代入
labels = X_train.columns
importance = model.feature_importances_
# 各特徴量の重要度をグラフ化
plt.figure(figsize=(10, 6))
plt.barh(y=range(len(importance)), width=importance)
plt.yticks(ticks=range(len(labels)), labels=labels)
plt.show()
このプログラムを実行すると、次のような予測が出力されます。

今回の予測モデルの正解率は61.3%となりました。特徴量エンジニアリング次第では、正解率を上げていくことも可能です。
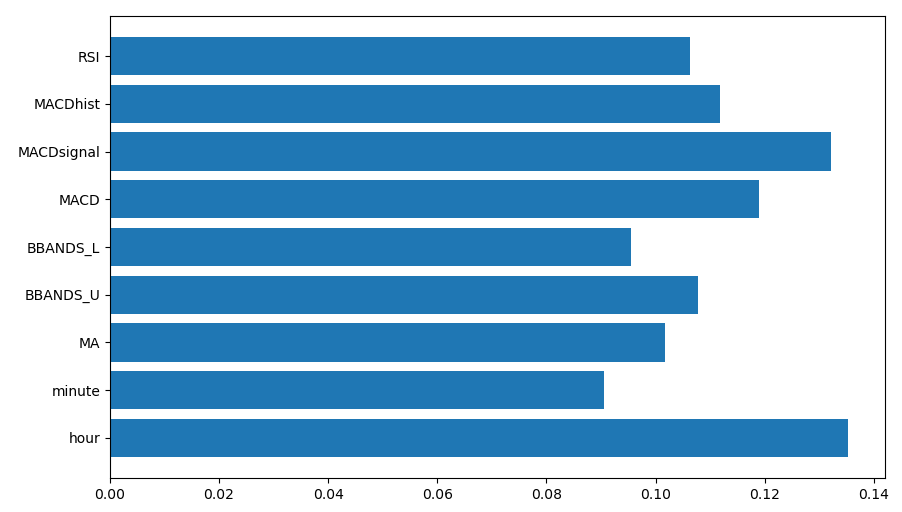
また、各特徴量の重要度のグラフが出力されます。今回はhour(時間)が最も重要な特徴量で、minute(分)が重要度の低い特徴量だったということが視覚的にわかります。
ポイントの解説
FXの価格データを取得
# FXの価格データを取得
pair = "USDJPY=X" # ドル/円
timeframe = "5m" # 5分足
number_of_days = 60 # 四本値を取得する日数
start = datetime.today().date() - timedelta(days=1)
end = datetime.today().date()
df = yf.download(pair, interval=timeframe, start=start)
for i in range(number_of_days):
start = start - timedelta(days=1)
end = end - timedelta(days=1)
df_reserve = yf.download(pair, interval=timeframe, start=start, end=end)
df = pd.concat([df_reserve, df])
time.sleep(0.1)まずは取得する価格データの設定を行います。
pairで通貨ペアを指定します。今回は米ドル/円ですが、他の通貨ペアにする場合は変更してください。
timeframeで時間足を変更できます。
number_of_daysは、本日から指定した日数分の過去のデータを取得します。5分足の場合は、60日前のデータまでしか取得できなかったので60としています。
yfinanceの使い方については、下記の記事を参考にしてください。
価格を取得する手順ですが、まず本日のデータを取得しています。そして前日以降は、for文で1日ずつ取得日をずらしてデータを取得しています。
ターゲット変数の作成
# ターゲット変数の作成
# 現在の価格と60分後の価格を比較して、上昇なら1、下降なら0とする
df['future_price'] = df['Close'].shift(-12) # 60分後の価格
columns = ['Close', 'future_price']
df_reserve = df[columns].diff(axis=1)
df_reserve['Close_diff'] = df_reserve['future_price']
df = pd.concat([df, df_reserve['Close_diff']], axis=1)
df['target'] = (df['future_price'] > df['Close']).astype(int)
df = df.dropna(subset=['future_price'])XGBoostは教師あり学習です。つまり3時間後の価格が上昇しているか、下降しているかのラベルを付ける必要があります。
df['future_price'] = df['Close'].shift(-36)で2時間分の価格をずらしたfuture_priceという列を作ります。5分足を使用しているので、df['Close'].shift(-36)で終値を36行ずらすと3時間後の価格がわかります。df_reserve = df[columns].diff(axis=1)で終値と3時間後の価格の差を計算しています。最後にdf['target'] = (df['future_price'] > df['Close']).astype(int)で、上昇なら1、下降なら0になるようにしています。
特徴量エンジニアリング
# 特徴量エンジニアリング
# 移動平均やボラティリティ、価格変化率などを特徴量にする
df['date'] = df.index.values
df['hour'] = df['date'].dt.hour
df['minute'] = df['date'].dt.minute
df['MA'] = talib.MA(df['Close'], timeperiod=20).diff()
df['BBANDS_U'], _, df['BBANDS_L'] \
= talib.BBANDS(df['Close'], timeperiod=20, nbdevup=2, nbdevdn=2, matype=0)
df['BBANDS_U'] = df['BBANDS_U'].diff()
df['BBANDS_L'] = df['BBANDS_L'].diff()
df['MACD'], df['MACDsignal'], df['MACDhist'] \
= talib.MACD(df['Close'], fastperiod=12, slowperiod=26, signalperiod=9)
df['RSI'] = talib.RSI(df['Close'], timeperiod=14)特徴量エンジニアリングとは、機械学習モデルの性能を向上させるために、大量のデータから有用な特徴量を作成・選択・変換することです。
FXの場合は、インジケーターの値を特徴量にすることができます。
今回は、移動平均線、ボリンジャーバンド、MACD、RSIを特徴量にしています。インジケーターの計算はTA-Libを使用しています。TA-Libの使い方については、下記の記事を参考にしてください。
特徴量エンジニアリングは、機械学習において重要な要素です。別のインジケーターを追加してみたり、パラメーターを変更したりして、予測の精度が上がるように調整してみてください。
予測モデルの作成
# 訓練データとテストデータに分割
features = ['hour', 'minute', 'MA', 'BBANDS_U', 'BBANDS_L', 'MACD', 'MACDsignal', 'MACDhist', 'RSI']
X = df[features]
y = df['target']
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 学習モデルを作成
model = xgb.XGBClassifier(n_estimators=100, max_depth=6, learning_rate=0.1, random_state=0)
# 学習モデルにテストデータを与えて学習させる
model.fit(X_train, y_train)上記のコードで肝となる機械学習をしています。Pythonでは機械学習もシンプルなコードで実行することができます。
まず、使用する特徴量と目的変数を指定します。
次にtrain_test_split()で、訓練データとテストデータに分割します。このコードでは、7:3に分割しています。訓練データで学習をして、テストデータで学習したモデルの検証を行います。
そして、XGBoostで学習させます。学習にはしばらく時間がかかります。
予測モデルの確認
# テストデータを与えて各データの種類を推測
test = model.predict(X_test)
# テストデータのラベルを与えて答え合わせ
score = accuracy_score(y_test, test)
print(f"正解率:{score * 100:.1f}%")
# 直近のデータで60分後の価格予測
latest_data = X.iloc[-1].values.reshape(1, -1)
prediction = model.predict(latest_data)
print(f'60分後の価格予測: {"上昇" if prediction[0] == 1 else "下降"}')
# 各特徴量の重要度の代入
labels = X_train.columns
importance = model.feature_importances_
# 各特徴量の重要度をグラフ化
plt.figure(figsize=(10, 6))
plt.barh(y=range(len(importance)), width=importance)
plt.yticks(ticks=range(len(labels)), labels=labels)
plt.show()作成した予測モデルの確認をします。
accuracy_score(y_test, test)のメソッドで予測モデルの正解率を計算できます。今回の予測モデルの正解率は、61.3%でした。
そして最も重要な60分後の予測をprediction = model.predict(latest_data)で行います。この予測モデルをもとに60分後の価格を予測をすると、下降するという予測になりました。
最後に各特徴量の重要度のグラフを出力します。特徴量エンジニアリングをする際の参考になります。
おわりに
この記事では、Pythonを使って1時間後の価格が現在の価格より上昇するか下降するかを予測プログラムを作成する方法を解説しました。
Pythonはコードがシンプルなので、初心者でも比較的簡単に機械学習を実装することができます。
バイナリーオプションの正解率を上げるためには、特徴量の選択とパラメーターの調整が重要な要素になります。
正解率が上げられるように、皆さんもチャレンジしてみてください。
\口座開設と取引で5,000円のボーナス!/

