
この記事には広告を含む場合があります。
記事内で紹介する商品を購入することで、当サイトに売り上げの一部が還元されることがあります。
レラティブストレングスは、「オニールの成長株発掘法」の著者のウィリアム・J・オニール氏が運営している投資情報サイトのインベスターズ・ビジネス・デイリー(IBD)が独自に開発した評価法で、計算方法は公開されていません。インベスターズ・ビジネス・デイリーの会員になれば利用することができますが、米国株を対象としているので日本株の情報はありません。
しかし、過去の株価の上昇率を相対的に比較した指標であるので、過去の株価が分かればPythonを用いて比較的簡単に計算することができます。
本記事では、レラティブストレングスの説明とPythonで計算する方法について解説します。
レラティブストレングスとは
レラティブストレングス(Relative Strength, RS)は、株式投資において、特定の銘柄が市場全体と比較してどれだけ強いかを評価するための指標です。
アメリカ屈指の投資家であるウィリアム・J・オニール氏の著書「オニールの成長株発掘法」やマーク・ミネルヴィニ氏の著書「ミネルヴィニの成長株投資法」で、重要な指標として紹介されています。
レラティブストレングス指数とは、『インベスターズ・ビジネス・デイリー』紙が独自に開発した評価法で、ある特定の銘柄の値動きを市場の残りの銘柄の動きと過去52週間にわたり比較するものだ。そしてその評価として各銘柄に1〜99の数値が割り当てられる(99が最高)。例えば、レラティブストレングス指数が99の場合は、その銘柄の値動きは市場全体の99%の企業を上回ったことを意味している。レラティブストレングス指数が50の場合は、市場の銘柄の半分がその銘柄よりも良い動きをし、残りの半分が悪い動きだったことを意味する。
引用:オニールの成長株発掘法
この2冊は投資家にとって有益な情報がたくさん書かれているので、一読の価値ありです。

オニールの成長株発掘法
オニール氏が著書で提唱している投資法「CAN-SLIM」で、銘柄選定で重要な指標のひとつとしてレラティブストレングスがです。
「CAN-SLIM」とは、銘柄選定で重要となる7項目の頭文字を表しています。それぞれの内容は次の通りです。
- Current Quarterly Earnings
当期四半期のEPSと売り上げ - Annual Earnings Increases
年間EPSの増加 - Newer Companies, New Products, New Management, New Highs Off Properly Formed Bases
新興企業、新製品、新経営陣、正しい株価ベースを抜けて新高値 - Supply and Demand
株式の需要と供給 - Leader or Laggard
主導銘柄か、停滞銘柄か - Institutional Sponsorship
機関投資家による保有 - Market Direction
株式市場の方向
この内のLeader or Laggard(主導銘柄か、停滞銘柄か)で、レラティブストレングスが80以上が主導銘柄とされおり、停滞銘柄は避けることとされています。
ミネルヴィニの成長株投資法
ミネルヴィニ氏が著書で提唱している投資法「トレンドテンプレート」の条件のひとつにレラティブストレングスが採用されています。70以上、望ましくは80台から90台とされています。
トレンドテンプレートとは、株価の上昇局面を見極める条件をまとめたもので、全部で8つあります。それぞれの内容は次の通りです。
- 現在の株価が150日(30週)と200日(40週)の移動平均線を上回っている。
- 150日移動平均線は200日移動平均線を上回っている。
- 200日移動平均線は少なくとも1ヶ月上昇トレンドにある。
- 50日(10週)移動平均線は150日移動平均線と200日移動平均線を上回っている。
- 現在の株価は50日移動平均線を上回っている。
- 現在の株価は52週安値よりも、少なくとも30%高い。
- 現在の株価は52週高値から少なくとも25%以内にある。
- レラティブストレングスのランキングは70%以上、望ましくは80台か90台である。
こちらは、レラティブストレングスが70%以上、望ましくは80台か90台とされています。

レラティブストレングスの計算式
レラティブストレングスの正式な計算方法は公開されていませんし、知るすべはありません。
しかし、ネットで「レラティブストレングスの計算式」と検索するといくつか情報が出てくるので、次の式を採用します。
((((C – C63) / C63) * 0.4) + (((C – C126) / C126) * 0.2) + (((C – C189) / C189) * 0.2) + (((C – C252) / C252) * 0.2)) * 100
- C:直近の株価
- C63:63営業日前の株価(3ヶ月前の株価)
- C126:126営業日前の株価(6ヶ月前の株価)
- C189:189営業日前の株価(9ヶ月前の株価)
- C252:252営業日前の株価(12ヶ月前の株価)
この計算式は、過去の株価と現在の株価を比較して、上昇しているほど結果の数値が高くなるようになっています。さらに、3ヶ月前のところで0.4、それ以外は0.2の係数をかけているので、直近の株価の上昇に対する感度を高めています。
そして、数値の高い順に並べ替えて、1から99の数字を振り分けることでランキングにすることができます。
この計算式のランキングは、本家のランキングと概ね合致するようです。
Pythonでレラティブストレングスを計算する方法
レラティブストレングスの計算式がわかったので、後はPythonで計算をします。
プログラムの大まかな流れは次の通りです。
- yfinanceで日本株の12ヶ月前までの株価を取得する。
- 各銘柄ごとのレラティブストレングスを計算する。
- レラティブストレングスの数値の降順で並べ替えて、1から99の数値を割り当てる。
- 割り当てられた数値が80以上の銘柄を切り分ける。
- データをエクセルファイルで出力する。
yfinanceをインストール
コマンドプロンプトで、株価データを取得するためのPythonライブラリyfinanceをpipでインストールします。
pip install yfinanceまたは、PyCharmの画面下部のPythonパッケージをクリックして、yfinanceを検索、インストールをクリックして最新のバージョンを選択するとインストールできます。

yfinanceの詳しい使い方は、次の記事をご覧ください。
 【Python】yfinanceの使い方を徹底解説!日本株や米国株の株価データや財務情報、為替データを取得する方法
【Python】yfinanceの使い方を徹底解説!日本株や米国株の株価データや財務情報、為替データを取得する方法
レラティブストレングスを計算するサンプルコード
import datetime
import pandas as pd
import yfinance as yf
# 株価を取得する関数
def get_data():
df = pd.DataFrame(columns=['code', '銘柄名', 'price', 'c63_price', 'c126_price', 'c189_price', 'c252_price'])
csv_df = pd.read_csv('screener_result.csv', header=None, skiprows=1, usecols=[0, 1])
df['code'] = csv_df[0]
df['銘柄名'] = csv_df[1]
start = datetime.datetime.today().date() - datetime.timedelta(days=365)
end = datetime.date.today()
ticker_symbol_dr = []
for i in range(len(df)):
ticker_symbol_dr.append((df.iloc[i, 0]) + ".T")
symbol_data = yf.download(ticker_symbol_dr, start=start, end=end)
df_code = pd.DataFrame(symbol_data['Close'])
for i in range(len(df)):
df.iat[i, 2] = df_code.iat[-1, i]
df.iat[i, 3] = df_code.iat[-63, i]
df.iat[i, 4] = df_code.iat[-126, i]
df.iat[i, 5] = df_code.iat[-189, i]
df.iat[i, 6] = df_code.iat[0, i]
df = df.dropna(how='any')
return df
# レラティブストレングスを計算する関数
def calculate_rs(rs_data):
rs = ((((rs_data['price'] - rs_data['c63_price']) / rs_data['c63_price']) * 0.4) +
(((rs_data['price'] - rs_data['c126_price']) / rs_data['c126_price']) * 0.2) +
(((rs_data['price'] - rs_data['c189_price']) / rs_data['c189_price']) * 0.2) +
(((rs_data['price'] - rs_data['c252_price']) / rs_data['c252_price']) * 0.2)) * 100
return rs
# リストを並べ替えて数値を割り当てる関数
def sorting_rs(sorting_rs_data):
sorting_rs_data = sorting_rs_data.sort_values('RS', ascending=False)
division = round(len(sorting_rs_data) / 99)
i = 99
j = 0
for k in range(len(sorting_rs_data)):
sorting_rs_data.iat[k, 7] = i
j += 1
if j == division:
i -= 1
j = 0
return sorting_rs_data[sorting_rs_data['RS'] >= 80]
data = get_data()
data["RS"] = data.apply(calculate_rs, axis=1)
data = sorting_rs(data)
data.to_excel(r'レラティブストレングス ' + str(datetime.date.today()) + '.xlsx')
証券コードのリストの用意
次に、上記のコードで使用する証券コードのリストを用意します。
おすすめの方法は、SBI証券の銘柄スクリーニングでCSVをダウンロードする方法です。東証P、東証S、東証Gにチェックを入れて、CSVダウンロードをクリックするとscreener_result.csvというファイル名のデータが手に入ります。
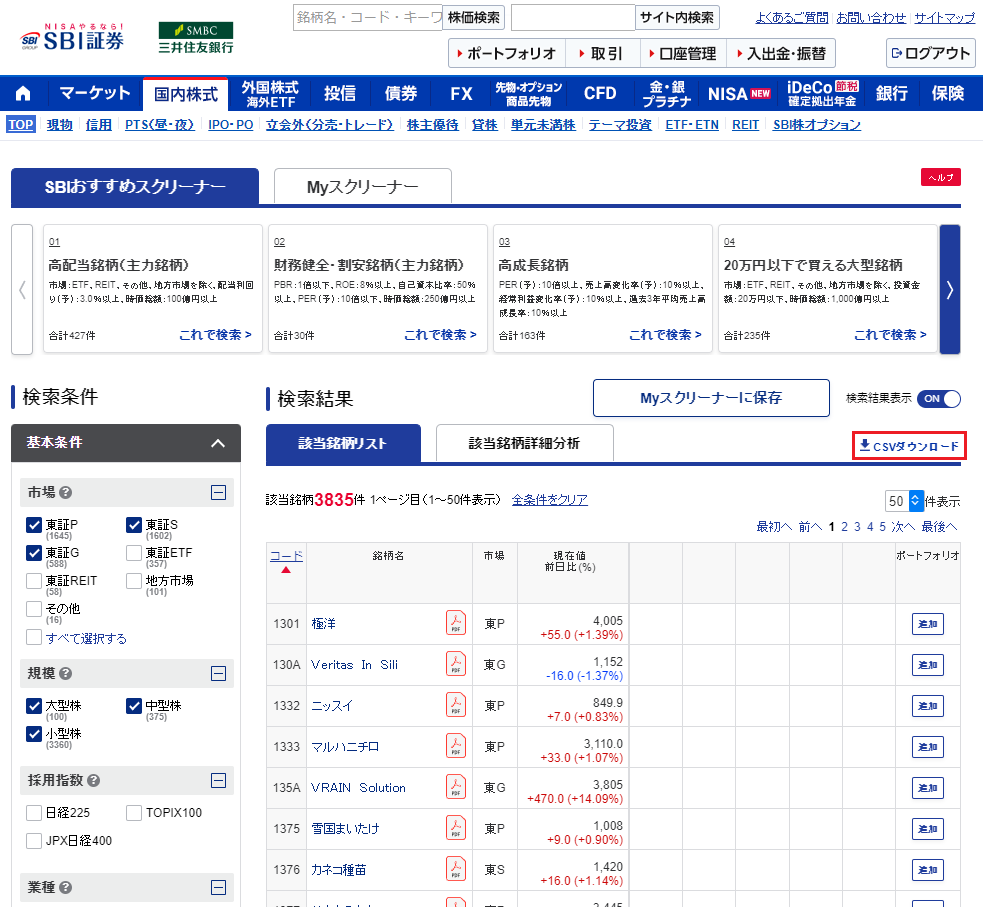
そして、ダウンロードしたscreener_result.csvを上記のコードが保存されているフォルダに移動させておきます。
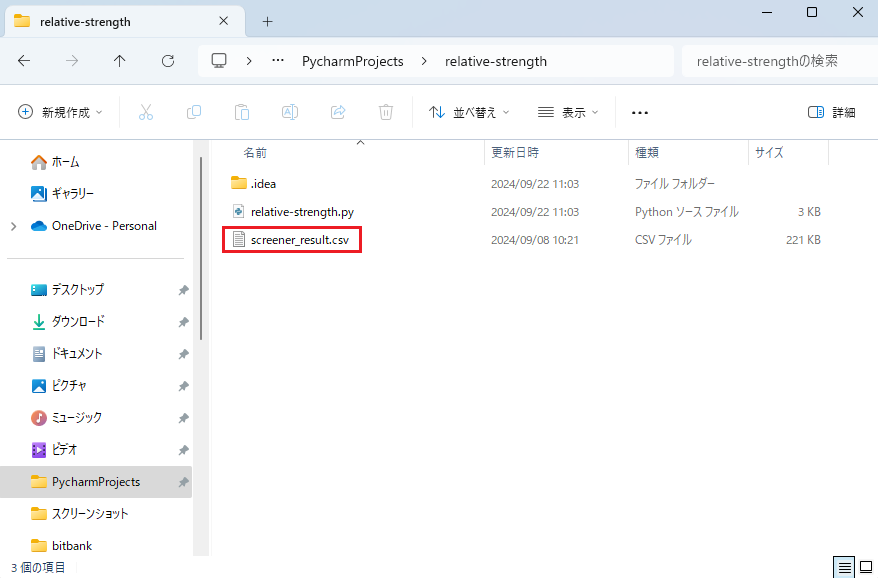
検索条件を変更してスクリーニングしたCSVもダウンロードできるので、スクリーニングされた証券コードのリストが欲しいときにも活用できます。
ポイントの解説
次にポイントとなるところを解説します。
株価の取得
# 株価を取得する関数
def get_data():
df = pd.DataFrame(columns=['code', '銘柄名', 'price', 'c63_price', 'c126_price', 'c189_price', 'c252_price'])
csv_df = pd.read_csv('screener_result.csv', header=None, skiprows=1, usecols=[0, 1])
df['code'] = csv_df[0]
df['銘柄名'] = csv_df[1]
start = datetime.datetime.today().date() - datetime.timedelta(days=365)
end = datetime.date.today()
ticker_symbol_dr = []
for i in range(len(df)):
ticker_symbol_dr.append((df.iloc[i, 0]) + ".T")
symbol_data = yf.download(ticker_symbol_dr, start=start, end=end)
df_code = pd.DataFrame(symbol_data['Close'])
for i in range(len(df)):
df.iat[i, 2] = df_code.iat[-1, i]
df.iat[i, 3] = df_code.iat[-63, i]
df.iat[i, 4] = df_code.iat[-126, i]
df.iat[i, 5] = df_code.iat[-189, i]
df.iat[i, 6] = df_code.iat[0, i]
df = df.dropna(how='any')
return df株価データを取得するための関数を作成します。
カラム名を証券コードと銘柄名、現在の価格と過去の価格にしてDataFrameを作成しておきます。
csv_df = pd.read_csv('screener_result.csv', header=None, skiprows=1, usecols=[0, 1])で、先程ダウンロードしたscreener_result.csvを読み込んで、DataFrameに証券コードと銘柄名を代入しています。
yfinanceで株価を取得する場合は、証券コードの末尾に「.T」を付ける必要があります。for文で「.T」を付けながら、リストに証券コードを追加しています。
yf.download(ticker_symbol_dr, start=start, end=end)で株価を取得します。開始日は本日で、終了日は365日前です。
次にDataFrameに過去の各ポイントの終値データを移します。
最後にdf = df.dropna(how='any')で、上場して1年未満の場合などで株価が無い銘柄を除外しています。
レラティブストレングスの計算
# レラティブストレングスを計算する関数
def calculate_rs(rs_data):
rs = ((((rs_data['price'] - rs_data['c63_price']) / rs_data['c63_price']) * 0.4) +
(((rs_data['price'] - rs_data['c126_price']) / rs_data['c126_price']) * 0.2) +
(((rs_data['price'] - rs_data['c189_price']) / rs_data['c189_price']) * 0.2) +
(((rs_data['price'] - rs_data['c252_price']) / rs_data['c252_price']) * 0.2)) * 100
return rs
レラティブストレングスを計算するための関数を作成します。
前述した計算式です。
この計算もプログラミングなら一瞬で終わります。
レラティブストレングスの並べ替え
# リストを並べ替えて数値を割り当てる関数
def sorting_rs(sorting_rs_data):
sorting_rs_data = sorting_rs_data.sort_values('RS', ascending=False)
division = round(len(sorting_rs_data) / 99)
i = 99
j = 0
for k in range(len(sorting_rs_data)):
sorting_rs_data.iat[k, 7] = i
j += 1
if j == division:
i -= 1
j = 0
return sorting_rs_data[sorting_rs_data['RS'] >= 80]計算されたレラティブストレングスを基に、銘柄を並べ替え、1から99の数値を割り当てる関数を作成します。
sorting_rs_data.sort_values('RS', ascending=False)で、レラティブストレングスの降順で並べ替えをしています。
そしてround(len(sorting_rs_data) / 99)で、1~99の数値に割り当てられる1個あたりの銘柄の数を計算しています。割り切れるものではないので、1~99に均等に分けれるものではありません。
for文で1~99の数値を割り振ります。先ほど計算した数値をカウントして、条件を満たすとランキングの数値が下がるようになっています。
最後にレラティブストレングスが80以上の銘柄だけを返しています。
メイン処理
data = get_data()
data["RS"] = data.apply(calculate_rs, axis=1)
data = sorting_rs(data)
data.to_excel(r'レラティブストレングス ' + str(datetime.date.today()) + '.xlsx')
最後に、上記の関数を使用してレラティブストレングスを計算し、エクセルファイルとして出力するメイン処理を作成します。
メインの処理は4行です。
ポイントは、Pandasのapply()を使用しているところです。今回のように銘柄ごとにレラティブストレングスの計算を繰り返すような場合は、for文で繰り返して計算するよりapply()を使用した方が処理時間が少なくなります。
最後にdata.to_excel(r'レラティブストレングス ' + str(datetime.date.today()) + '.xlsx')で、「レラティブストレングス(本日の日付).xlsx」というファイル名でエクセルファイルを出力します。
まとめ
以上の手順で、Pythonを使ってレラティブストレングスを計算して主導銘柄を見つけることができます。これにより、停滞銘柄を避け、パフォーマンスを向上させることが期待できます。
しかし、今回計算したレラティブストレングスが80以上の銘柄は、740銘柄ありました。さらにスクリーニングする必要があります。
オニール氏の「CAN-SLIM」やミネルヴィニ氏の「トレンドテンプレート」をPythonでさらに詳細なスクリーニングを行うことも可能です。
ぜひともチャレンジしてみてください。
参考文献
- ウィリアム・J・オニール「オニールの成長株発掘法」、パンローリング (2011/4/15)
- マーク・ミネルヴィニ「ミネルヴィニの成長株投資法 ━━高い先導株を買い、より高値で売り抜けろ」、パンローリング (2013/12/14)


