
この記事には広告を含む場合があります。
記事内で紹介する商品を購入することで、当サイトに売り上げの一部が還元されることがあります。
Pythonは、AI(人工知能)に関連するライブラリが充実しているプログラミング言語です。コードがシンプルで理解しやすいので、初心者でもAI開発が可能です。
特に過去のデータを学習して未来を予測するような機械学習においては、FXとの相性も良いはずです。
本記事では、AIでFXの価格を予測して自動売買プログラムに実装するまでの手順を解説を解説します。
まだ自動売買の環境が整っていない方は、下記の記事を順番に読み進めていくことで自動売買プログラムの作成方法を学ぶことができます。
 【初心者向け】FXの自動売買プログラムをPythonで自作しよう①
【初心者向け】FXの自動売買プログラムをPythonで自作しよう①
AIの学習手法について
AIの学習手法は大きく4つに分類できます。
- 教師あり学習
- 教師なし学習
- 強化学習
- ディープラーニング
FXの場合は、過去の価格データを使用することである時間での未来の価格はわかっているので、正解となるデータを与えて学習をさせる手法の教師あり学習を採用します。
しかし、教師あり学習であっても正確な未来の価格を予想することは難しいと思います。ただ、近い未来の価格が一定価格より変動するかしないかの2択だったら予想はしやすいと思います。
よって、精度の高い予測ができるランダムフォレストで、近い未来の価格が一定価格より変動するかしないかを分類するAIを開発します。
ランダムフォレストとは、複数の決定木を集めて多数決をとる分析手法です。 機械学習の分類や回帰といった用途で用いられます。 決定木よりも高い精度を出せる点が特徴です。
具体的には、「過去30分の特徴量から、10分後の価格変動が過去の平均以上になるか否か」を分類します。
scikit-learnでランダムフォレストを実装
scikit-learnのインストール
pipでscikit-learnのインストールをします。
scikit-learn は Python のオープンソース機械学習ライブラリです。分類、回帰、ランダムフォレスト、クラスタリング、次元削減、モデル選択、前処理などの機能が利用できます。
pip install -U scikit-learnAI学習プログラム
まずは上昇の予測(買い)をします。下降の予測(売り)は、必要なところのプログラムを変更をしてください。
今回作成したプログラムは次のようになります。
import requests
import time
from datetime import datetime
from datetime import timedelta
import pandas as pd
import talib
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pickle
# 設定項目
interval = '1min' # 使用する時間軸
get_price_period = 100 # 四本値を取得する日数
# 四本値を取得する関数
def get_price_data():
while True:
try:
price_data = []
response_data = []
if 0 <= datetime.today().hour <= 5:
today = datetime.today().date()
else:
today = datetime.today().date() + timedelta(days=1)
for i in range(get_price_period):
period = i - get_price_period
date = (today + timedelta(days=period)).strftime('%Y%m%d')
endPoint = 'https://forex-api.coin.z.com/public'
path = '/v1/klines?symbol=USD_JPY&priceType=ASK&interval=' + interval + '&date=' + date
response = requests.get(endPoint + path)
response_data.append(response.json())
for j in range(len(response_data)):
for i in response_data[j]['data']:
price_data.append({'openTime': i['openTime'],
'openTime_dt': datetime.fromtimestamp(int(i['openTime'][:-3]))
.strftime('%Y/%m/%d %H:%M'),
'open': float(i['open']),
'high': float(i['high']),
'low': float(i['low']),
'close': float(i['close'])})
df_price_data = pd.DataFrame(price_data)
return df_price_data
except Exception as e:
print(f'action=get_price_data error={e}')
print('10秒後にリトライします')
time.sleep(10)
# float型に変換する関数
def convert_to_float(data):
return float(data)
# 目的変数にラベルを付ける関数
def judge_the_above_average(data):
if data < 0:
return 0
else:
return 1
fx_data = get_price_data()
# 各特徴量の計算
fx_data['MA'] = talib.MA(fx_data['close'], timeperiod=30).diff()
fx_data['BBANDS_U'], _, fx_data['BBANDS_L'] = talib.BBANDS(fx_data['close'], timeperiod=30, nbdevup=2, nbdevdn=2, matype=0)
fx_data['BBANDS_U'] = fx_data['BBANDS_U'].diff()
fx_data['BBANDS_L'] = fx_data['BBANDS_L'].diff()
fx_data['MACD'], fx_data['MACDsignal'], fx_data['MACDhist'] = talib.MACD(fx_data['close'], fastperiod=12, slowperiod=26, signalperiod=9)
fx_data['RSI'] = talib.RSI(fx_data['close'], timeperiod=30)
# 10分後までの高値をmaxに代入
fx_data['max'] = ''
for i in range(len(fx_data)):
fx_data.iat[i, -1] = float(fx_data.iloc[i:i + 10, [3]].max())
# 10分後までの高値と現在の終値の差を計算してfloat型に変換
fx_data['high_diff'] = (fx_data['max'] - fx_data['close']).apply(convert_to_float)
# 10分後の高値の平均値を計算して箱ひげ図を出力
high_diff_mean = round(fx_data['high_diff'].describe().loc['mean'], 3)
print(f"10分後の高値の平均値:{high_diff_mean}")
fx_data['high_diff'].plot.box()
# 10分後の高値の差が平均値以上の場合にラベルを付ける
fx_data['above_average'] = (fx_data['high_diff'] - high_diff_mean).apply(judge_the_above_average)
# 欠損値のある行を削除
fx_data = fx_data.dropna(how='any')
# 使用する特徴量と目的変数を指定
fx_data.data = fx_data.loc[:, ['MA', 'BBANDS_U', 'BBANDS_L', 'MACD', 'MACDsignal', 'MACDhist', 'RSI']]
fx_data.target = fx_data.loc[:, ['above_average']]
# 訓練データとテストデータに分割
x_train, x_test, t_train, t_test = train_test_split(fx_data.data, fx_data.target, test_size=0.3, random_state=0)
# 学習モデルを作成
model = RandomForestClassifier()
# 学習モデルにテストデータを与えて学習させる
model.fit(x_train, t_train)
# テストデータを与えて各データの種類を推測
test = model.predict(x_test)
# テストデータのラベルを与えて答え合わせ
score = accuracy_score(t_test, test)
print(f"正解率:{score * 100}%")
# 学習モデルの保存
with open('random_forest_buy_model.pickle', mode='wb') as f:
pickle.dump(model, f, protocol=2)
# 各特徴量の重要度の代入
labels = x_train.columns
importance = model.feature_importances_
# 各特徴量の重要度をグラフ化
plt.figure(figsize=(10, 6))
plt.barh(y=range(len(importance)), width=importance)
plt.yticks(ticks=range(len(labels)), labels=labels)
plt.show()基本的にはコメントで解説していますが、ポイントとなるところを解説します。
ポイントの解説
価格データの取得
# 設定項目
interval = '1min' # 使用する時間軸
get_price_period = 100 # 四本値を取得する日数
# 四本値を取得する関数
def get_price_data():
while True:
try:
price_data = []
response_data = []
if 0 <= datetime.today().hour <= 5:
today = datetime.today().date()
else:
today = datetime.today().date() + timedelta(days=1)
for i in range(get_price_period):
period = i - get_price_period
date = (today + timedelta(days=period)).strftime('%Y%m%d')
endPoint = 'https://forex-api.coin.z.com/public'
path = '/v1/klines?symbol=USD_JPY&priceType=ASK&interval=' + interval + '&date=' + date
response = requests.get(endPoint + path)
response_data.append(response.json())
for j in range(len(response_data)):
for i in response_data[j]['data']:
price_data.append({'openTime': i['openTime'],
'openTime_dt': datetime.fromtimestamp(int(i['openTime'][:-3]))
.strftime('%Y/%m/%d %H:%M'),
'open': float(i['open']),
'high': float(i['high']),
'low': float(i['low']),
'close': float(i['close'])})
df_price_data = pd.DataFrame(price_data)
return df_price_data
except Exception as e:
print(f'action=get_price_data error={e}')
print('10秒後にリトライします')
time.sleep(10)まず、1分足のデータを100日分取得するように設定してます。
当ブログでは、GMOコインのAPIを利用して米ドル/円の価格データを取得しています。外国為替FXの自動売買に挑戦したい方は、GMOコインで口座開設することをおすすめします。
 GMOコインでFXの自動売買するための口座を開設してAPIを試そう【FXの自動売買プログラムをPythonで自作しよう④】
GMOコインでFXの自動売買するための口座を開設してAPIを試そう【FXの自動売買プログラムをPythonで自作しよう④】
GMOインターネットグループの暗号資産FX・売買サービス
- 新たに「外国為替FX」のAPIサービスを開始
- 口座開設申し込みから最短10分で取引が可能
- 現物取引、レバレッジ取引ともにサービスが充実している
- 取引ツールが高性能かつ使いやすい
特徴量の計算
# 各特徴量の計算
fx_data['MA'] = talib.MA(fx_data['close'], timeperiod=30).diff()
fx_data['BBANDS_U'], _, fx_data['BBANDS_L'] = talib.BBANDS(fx_data['close'], timeperiod=30, nbdevup=2, nbdevdn=2, matype=0)
fx_data['BBANDS_U'] = fx_data['BBANDS_U'].diff()
fx_data['BBANDS_L'] = fx_data['BBANDS_L'].diff()
fx_data['MACD'], fx_data['MACDsignal'], fx_data['MACDhist'] = talib.MACD(fx_data['close'], fastperiod=12, slowperiod=26, signalperiod=9)
fx_data['RSI'] = talib.RSI(fx_data['close'], timeperiod=30)機械学習では、大量のデータからパターンやルールを学習します。そこで、様々な種類のデータが必要となります。つまり特徴量が必要です。特徴量は、対象データの特徴を定量的な数値として表したものです。FXでは、インジケーターの値を特徴量にすることができます。
各特徴量の計算は、テクニカル分析ライブラリのTA-Libを使用しています。今回は、移動平均線、ボリンジャーバンド、MACD、RSIを特徴量にしています。移動平均線とボリンジャーバンドで差を取っている理由は、絶対的な価格で学習するよりも相対的な変化量でみたほうが効果があるように感じるからです。
また、特徴量は追加したりして色々試してみてください。
TA-Libの詳しい使い方は、次の記事を参考にしてください。
 【Python】テクニカル分析ライブラリTA-Libの使い方を解説
【Python】テクニカル分析ライブラリTA-Libの使い方を解説
目的変数の設定
# float型に変換する関数
def convert_to_float(data):
return float(data)
# 目的変数にラベルを付ける関数
def judge_the_above_average(data):
if data < 0:
return 0
else:
return 1
# 10分後までの高値をmaxに代入
fx_data['max'] = ''
for i in range(len(fx_data)):
fx_data.iat[i, -1] = float(fx_data.iloc[i:i + 10, [3]].max())
# 10分後までの高値と現在の終値の差を計算してfloat型に変換
fx_data['high_diff'] = (fx_data['max'] - fx_data['close']).apply(convert_to_float)
# 10分後の高値の平均値を計算して箱ひげ図を出力
high_diff_mean = round(fx_data['high_diff'].describe().loc['mean'], 3)
print(f"10分後の高値の平均値:{high_diff_mean}")
fx_data['high_diff'].plot.box()
# 10分後の高値の差が平均値以上の場合にラベルを付ける
fx_data['above_average'] = (fx_data['high_diff'] - high_diff_mean).apply(judge_the_above_average)
# 欠損値のある行を削除
fx_data = fx_data.dropna(how='any')教師あり学習では答えとなる目的変数が必要です。10分後までの高値の平均を計算して、平均以上となる行にラベルを付けます。
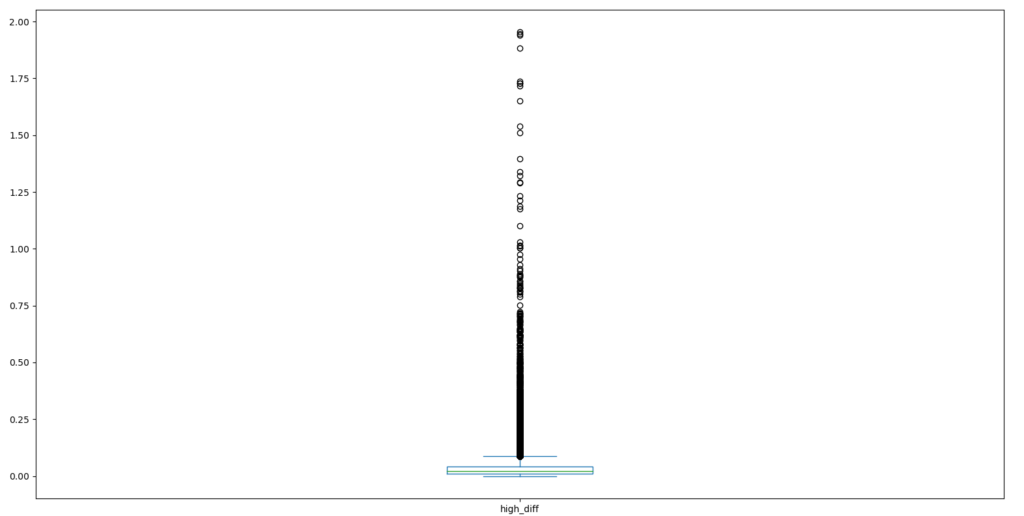
このプログラムでは箱ひげ図を出力するようにしています。10分後までの高値の平均値は0.035円で、ほとんどが0.1円以下に収まっていますが、外れ値も多く存在しています。
ランダムフォレストのモデルを作成
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pickle
# 使用する特徴量と目的変数を指定
fx_data.data = fx_data.loc[:, ['MA', 'BBANDS_U', 'BBANDS_L', 'MACD', 'MACDsignal', 'MACDhist', 'RSI']]
fx_data.target = fx_data.loc[:, ['above_average']]
# 訓練データとテストデータに分割
x_train, x_test, t_train, t_test = train_test_split(fx_data.data, fx_data.target, test_size=0.3, random_state=0)
# 学習モデルを作成
model = RandomForestClassifier()
# 学習モデルに訓練データを与えて学習させる
model.fit(x_train, t_train)
# テストデータを与えて予測
test = model.predict(x_test)
# 予測が合っているか答え合わせ
score = accuracy_score(t_test, test)
print(f"正解率:{score * 100}%")
# 学習モデルの保存
with open('random_forest_buy_model.pickle', mode='wb') as f:
pickle.dump(model, f, protocol=2)
上記のコードで肝となる機械学習をしています。Pythonでは機械学習もシンプルなコードで実行することができます。
まず、使用する特徴量と目的変数を指定します。
次に訓練データとテストデータに分割します。このコードでは、7:3に分割しています。
そして、ランダムフォレストで学習させます。学習にはしばらく時間がかかります。
学習が終了するとテストデータで予測をして、答え合わせをします。今回の正解率は、73%でした。
最後に自動売買で学習したモデルを使うために保存をします。
特徴量の重要度の確認
# 各特徴量の重要度の代入
labels = x_train.columns
importance = model.feature_importances_
# 各特徴量の重要度をグラフ化
plt.figure(figsize=(10, 6))
plt.barh(y=range(len(importance)), width=importance)
plt.yticks(ticks=range(len(labels)), labels=labels)
plt.show()scikit-learnでは特徴量の重要度を確認することができます。重要度のグラフを出力するようにしています。
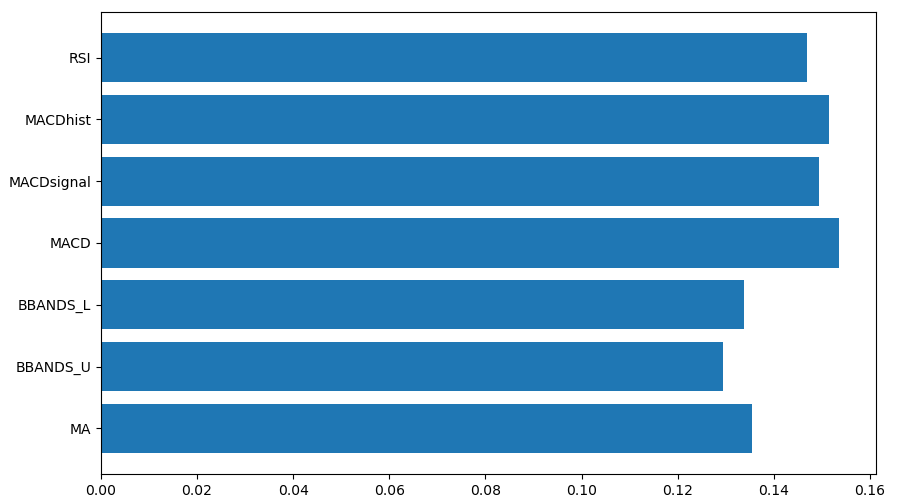
ほとんど同じような重要度です。著しく低い項目があるようでしたら、省いた方が精度が高くなるように思われます。
AIのモデルを自動売買プログラムに実装
それでは、AIで自動売買をする手順について解説します。
当ブログで解説している外国為替FXの自動売買プログラムで、変更が必要なところについて説明します。主にエントリーシグナルを出す関数に変更が必要です。
# ライブラリを追加
import talib
import pickle
# エントリーシグナルを出す関数を変更
def entry_signal(df):
global flag
# 各特徴量の計算
price['MA'] = talib.MA(price['close'], timeperiod=30)
price['BBANDS_U'], _, price['BBANDS_L'] \
= talib.BBANDS(price['close'], timeperiod=30, nbdevup=2, nbdevdn=2, matype=0)
price['BBANDS_U'] = price['BBANDS_U']
price['BBANDS_L'] = price['BBANDS_L']
price['MACD'], price['MACDsignal'], price['MACDhist'] \
= talib.MACD(price['close'], fastperiod=12, slowperiod=26, signalperiod=9)
price['RSI'] = talib.RSI(price['close'], timeperiod=30)
random_forest_data = price.dropna(how='any')
random_forest_data = random_forest_data.loc[:, ['MA', 'BBANDS_U', 'BBANDS_L',
'MACD', 'MACDsignal', 'MACDhist', 'RSI']]
# 学習モデルで予測
buy_prediction = random_forest_buy_model.predict(random_forest_data)
# ここに売りの予測を追加する
print('BUY:' + str(buy_prediction[-1]))
if buy_prediction[-1] == 1:
flag['order']['side'] = 'BUY'
print('買いのシグナルが発生しました。')
# ここに売りの判定を追加する
else:
flag['order']['side'] = None
return flag
# 買いの学習モデルを読み出す
with open('random_forest_buy_model.pickle', mode='rb') as f:
random_forest_buy_model = pickle.load(f)
# 売りの学習モデルを読み出すまず、先程作成した学習モデルを読み出す必要があります。売りのモデルも作成して、同様に読み出しましょう。
def entry_signal(df):では、学習のプログラムと同様の特徴量となるインジケーターの計算が必要です。そのデータをもとに学習モデルで予測をします。予測したデータの最後の値が「1」ならば今後上昇すると予測したことになり、買いのシグナルを出します。
おわりに
お疲れさまでした。
少し難しく感じるところもあったかもしれませんが、AIによる自動売買ができるようになりました。
特徴量や目的変数などの条件をいろいろ試してみて、正解率を上げるチャレンジをしてみてください。
また、今回紹介したランダムフォレスト以外にも様々な手法があるので、他の手法も試してみてはいかがでしょうか。

